영속성 관리 - 내부 동작 방식
JPA에서 가장 중요한 두가지
- 객체와 RDB 매핑하기
- 영속성 컨텍스트
영속성 컨텍스트
엔티티를 영구 저장하는 환경
엔티티의 생명주기
- 비영속 (new / transient)
- 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
- 영속 (managed)
- 영속성 컨텍스트에 관리되는 상태
- 준영속 (detached)
- 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제 (removed)
- 삭제된 상태
1. 비영속

Member member = new Member();
member.setId(1L);
member.setName("hello");
즉, 객체만을 만들어두고 다른 행위를 하지 않은 상태이다.
2. 영속

EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
em.persist(member);즉, 생성해둔 객체를 EntityManager를 통해서 저장해놓은 상태이다.
물론 persist로 영속상태에 둔다고 해서 db에 저장된다는 것은 아니다. db에 저장이되는 시점은 commit이 날아가는 시점이고 현재 상태는 "영속상태"에만 둔 상태이기 떄문에 이를 구분지어서 생각해야 한다.
3. 준영속
em.detach(member)
영속관계를 끊은 상태
4. 삭제
em.remove(member)
객체를 삭제한 상태
영속성 컨텍스트의 특징
1. 엔티티 조회, 1차 캐시
사실 조회를 하는데 있어서 두가지 경우가 있다.
- 영속 컨텍스트에서 바로 꺼내는 경우
- db에서 조회하는 경우
// 비영속
Member member = new Member();
member.setId(1L);
member.setName("HelloA");
System.out.println("=== before ===");
// 1차캐시, 영속 컨텍스트에 저장됨.
em.persist(member);
System.out.println("=== after ===");
// 1차캐시에서 바로 조회
Member findMember = em.find(Member.class, 1L);
System.out.println("findMember id : " + findMember.getId());
System.out.println("findMember name : " + findMember.getName());
tx.commit();
=== before ===
=== after ===
findMember id : 1
findMember name : HelloA
Hibernate:
/* insert hello.jpa.domain.Member
*/ insert
into
Member
(name, id)
values
(?, ?)
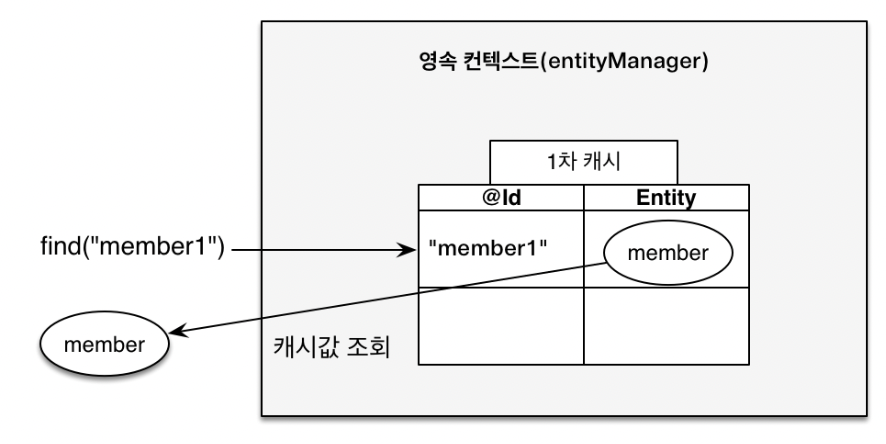
일단, 영속성 컨텍스트에서 바로 저장을 해둔 Member 객체가 있다.
이 상황에서 바로 조회를 한다면 db에서 조회를 하는 것이 아닌 영속성 컨텍스트에서 바로 조회를 해서 반환한다. 이는 출력에서 before after사이에서는 쿼리가 나가지 않음을 봄으로써 알 수 있다.
Member findMember1 = em.find(Member.class, "member2");
Member findMember2 = em.find(Member.class, "member2");
Hibernate:
select
member0_.id as id1_0_0_,
member0_.name as name2_0_0_
from
Member member0_
where
member0_.id=?
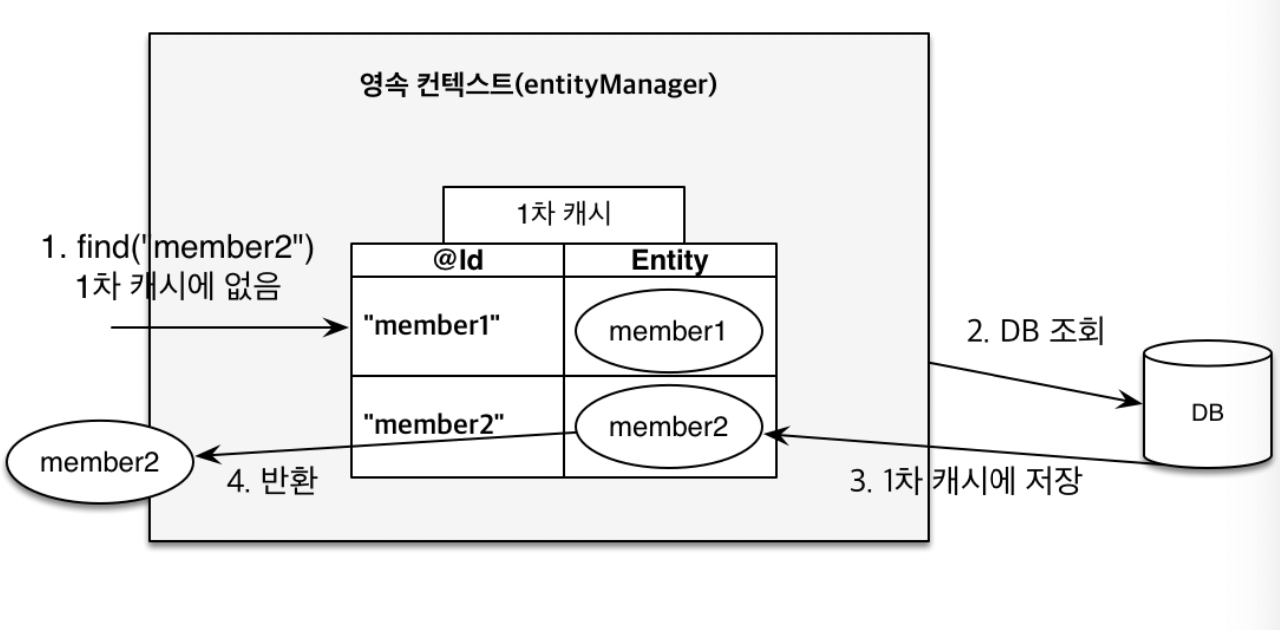
지금은 db에서 조회를 한번 하고 또 조회를 하는 상황이다.
영속성 컨텍스트에 해당하는 값이 없기 떄문에 첫 findMember1을 조회할 때는 쿼리가 나갔지만 두번째 부터는 해당되는 값에 대해서 캐시가 있기 때문에 쿼리가 다시 나가지 않은 모습이다.
??? 조회의 경우 find 메소드를 통해서 똑같이 사용하는데 왜 두가지 경우가 나뉘어져 있을까?
jpa에서 조회는 결국 순서가 정해져있기 때문이다. 항상 영속성 컨텍스트를 먼저 확인하는 쪽으로.
첫번째 케이스의 경우 영속성 컨텍스트에 조회를 먼저 해보니 해당 entity가 있어 반환을 한 것이고,
두번째 케이스의 경우 영속성 컨텍스트에 조회를 먼저 해보니 없어서 db에 조회를 해서 반환을 한 것이다.
결국 영속성 컨텍스트에 먼저 조회를 해서 캐싱의 개념을 사용한다는 것에 유의를 하면 되고, db에 조회를 하더라도 바로 반환을 하는 것이 아닌 1차 캐시에 마찬가지로 저장을 한 다음 반환을 한다는 사실을 유의해야한다. 다음과 같이 말이다.
// em.find(Member.class. "member2");
// mysql db조회
em.persist(new Member("member2", "회원2"));
return em.find("member2");
2. 영속 엔티티의 동일성 보장
똑같은 것을 db에서 조회했을 때 레퍼런스, 즉 객체의 참조값이 동일함을 보장하는 것이다.
아까 작성했던 코드를 보자.
Member findMember1 = em.find(Member.class, "member2");
Member findMember2 = em.find(Member.class, "member2");
System.out.println(findMember1 == findMember2);
// true
사실 DB에서 매핑하는 DAO로 이 둘을 가져왔다면 둘은 전혀 다른 객체 참조값을 가지게 될 것이다. 그때마다 객체를 생성하기 때문이다.
근데 지금까지 계속 이야기했던 것처럼 자바내에서 컬랙션에서 객체를 가져온다는 관점에서 보면 이둘은 당연히 같아야한다. JPA에서도 동일하게 이 둘의 동일성을 보장해 준다.
3. 엔티티 등록 시 트랜잭션을 지원하는 쓰기 지연
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
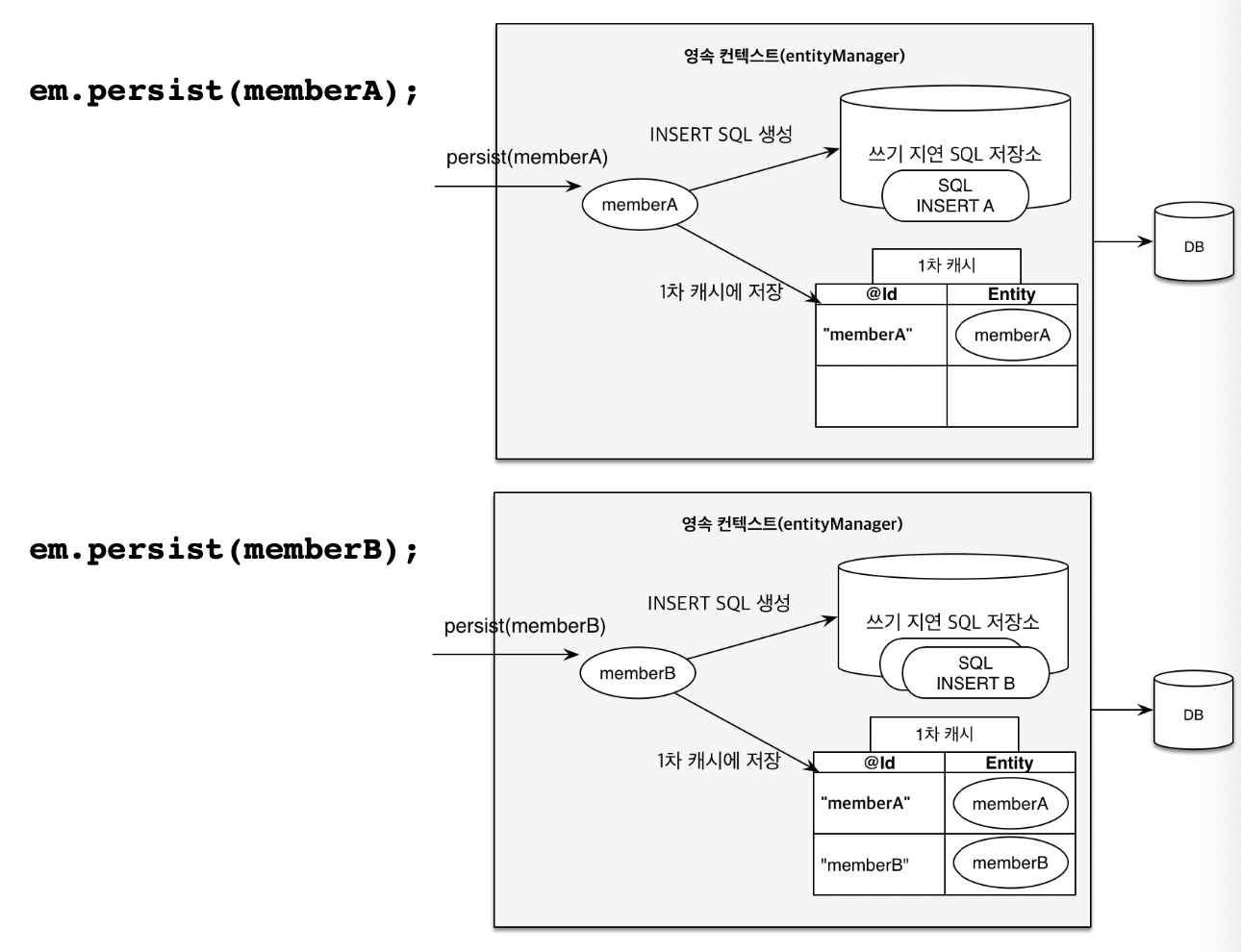
em.persist(memberA);
em.persist(memberB);
// 여기까지는 insert 쿼리를 날리지 않는다.
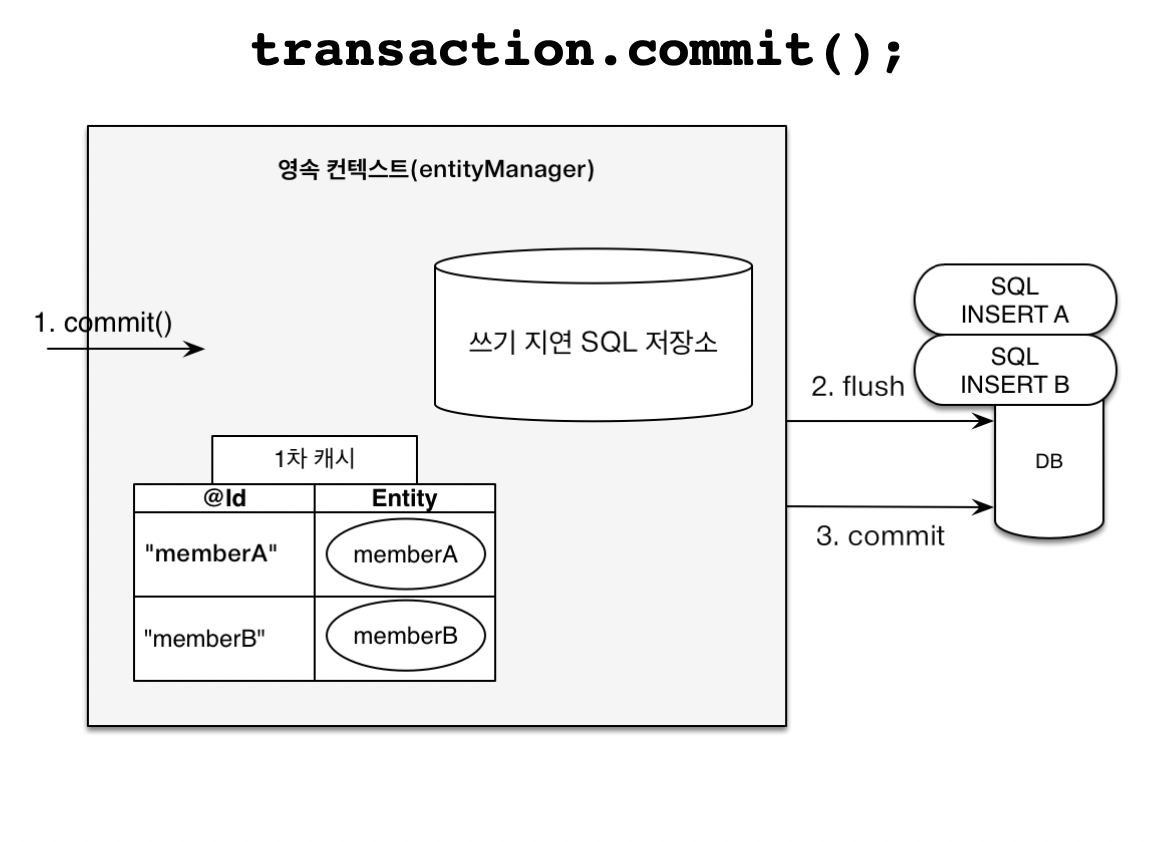
tx.commit();
// 여기에 insert 쿼리를 날린다.
조회는 아까전에 말했다시피 1차 캐시에서 먼저 검색을 하고, 없으면 db에 쿼리를 날려서 검색 후 1차 캐시에 저장하고 가져오는 방식으로 진행이 되었다.
근데 update, delete, insert 등 추가 삭제를 요구하는 메소드의 경우 "항상" 쿼리가 날아가는 시점은 commit이 된다.
cud를 한다고 해도 바로 쿼리로 날리는 것이 아닌 다음과 같이 쓰기 지연 저장소에 쿼리들을 저장해둔 상태에서,
이들을 commit하는 시점에 한번에 flush한다. 사실상 batch와 성격이 비슷하다고 볼 수 있다.
이때 한번에 commit에 쿼리를 모으는 것도 커스텀을 할 수 있기는 한데 batch size를 조정해서 변경할 수 있다.
근데 사실 JPA를 사용하면서 사용하는 Identity 생성 전략을 사용할 경우 db에 id 생성 사용을 인가하기 때문에 batch insert가 적용되지 않는다.
이 경우 다량의 데이터를 batch성으로 넣고 싶을 때는 Identity로 저장할 수 없기 때문에 JDBC의 batchUpdate()를 사용하거나 Batch SEQUENCE를 사용해야 한다.
4. 엔티티 수정 시 변경 감지(Dirty checking)
엔티티를 수정하게 되었을 때 과연 무언가 메소드를 날리고 요청해야할까?
아니다.
모든 jpa의 로직은 컬랙션을 생각해보면 된다. 컬랙션에서 객체를 꺼내와서 객체 값만 변경하면 알아서 컬랙션 내에 객체값이 변경되어있지 않은가? 즉, JPA에서는 Dirty checking이라는 것을 통해서 굳이 entity에 대한 변경 메소드를 호출하지 않아도 수정을 해준다.
// 영속 엔티티 조회 및 영속화
Member member A = em.find(Member.class, "memberA");
// 영속 엔티티 수정
memberA.setUsername("hi");
memberA.setAge(10);
transaction.commit();
이와 같이 따로 update 메소드를 날리지 않아도 업데이트쿼리가 날아간다. 어떻게 이렇게 되는지 알아보자.
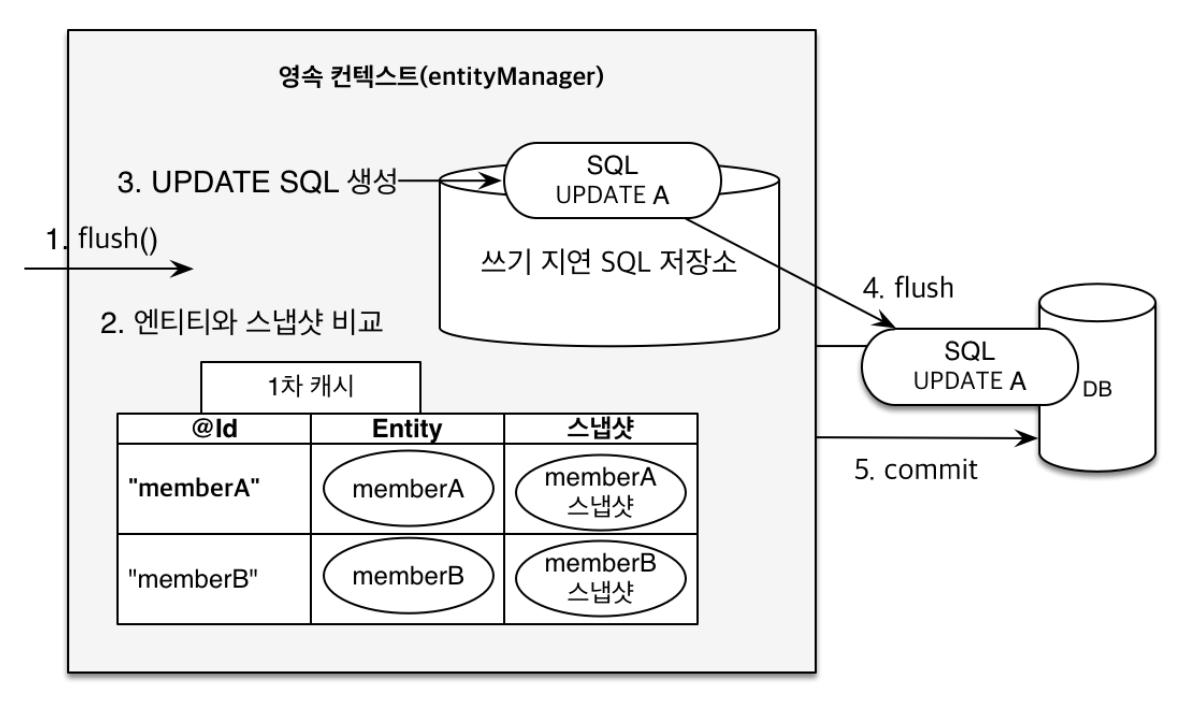
jpa는 db에서 혹은 persist에 1차 캐시로 영속 엔티티를 저장할 때 스냅샷이라는 저장소에 저장된 초기의 데이터를 저장한다. 따라서 commit을 하기 전 스냅샷 데이터와 현재 entity 데이터를 비교해서 알아서 commit을 할 때 update 쿼리를 날리게끔 지원해준다.
플러시
지금까지 영속성 컨텍스트에 대한 이야기를 하면서 쓰기 지연을 활용하는 과정에 flush라는 개념이 있었다.
플러시는 사실 별다른 어려운 특징이 있는 것이 아니라 쓰기 지연 저장소에서 db에 실제 쿼리가 나가는 것을 플러시라고 한다.
em.flush() - 직접 호출
transaction.commit() - 커밋 시 자동 호출
JPQL 쿼리 실행 - 자동 호출
음 위에 있는 둘의 경우 왜 저렇게 되는지 직관적으로 보면 이해가가는데 JPQL실행시 왜 자동으로 플러시가 호출되어야 할까?
일단 모든 쿼리들은 영속 컨텍스트에서 관리가 되고 있는 상황에서 JPQL는 이와 독립적으로 관리되는 쿼리이다. 즉, 내가 persist에 저장한 임의의 객체들이 JPQL 쿼리에서는 보장하고 있지 않기 때문에 JPQL과의 상호호환을 위해서라면 반드시 전에 플러시가 호출되어야 하는 것이다.
본 게시글은 김영한님의 자바 ORM 표준 JPA 프로그래밍을 정리한 글 입니다.